Introduction
AI Personal Workflow Assistant is an intelligent automation system that combines a REST API (FastAPI) with a workflow in n8n, integrating AI services (OpenAI) with storage (PostgreSQL) and caching (Redis). It allows for automated summarization of texts, translation of content, and classification of information, interacting with a Telegram bot or directly via API. Below is a detailed analysis of its components, overall functioning, portfolio evaluation, and presentation recommendations.
And if you want a more detailed analysis of the Backend, you can check the README.md or the GUIDE.md in the project’s Github repository.
1- What can this assistant do?
-
✅ Automatically summarize texts
You send a long block of text (for example, a news article, an email, or a report) and it returns the essentials in 3-5 sentences. Ideal for saving time. -
🌍 Translate with context
Translates between English and Spanish while maintaining nuances and the original tone. It is not a word-for-word translation, but one optimized for understanding. -
🧠 Intelligently classify content
Analyze the text to detect its urgency, sentiment, and category (e.g., complaint, suggestion, spam, etc.). Perfect for prioritizing tasks or alerts. -
📊 Consult your task history
Save what you have requested. You can ask things like:
“What translations did I do this week?” or “What documents did I classify yesterday?”. -
🤖 Use from Telegram or other systems
You can chat with the bot via Telegram as if it were a personal assistant, or integrate it via REST API with dashboards, apps, or other automated workflows.

2- Main features of the project
-
Telegram Bot Interface
• Text and voice commands to interact with the assistant.
• Contextual responses generated with GPT‑4o-mini, including summaries and personalized recommendations. -
REST API with FastAPI
• Endpoints to create tasks, manage workflows, and query histories.
• JWT-based authentication for users and external services. -
Visual orchestration with n8n
• Workflows that connect with the Backend and AI.
• Error handling, retries, and integrated notifications. -
Natural language processing with OpenAI
• Automatic summarization, translation, and classification of text and documents.
• Embeddings for semantic search and context retrieval (“RAG”). -
Persistence and State in PostgreSQL
• Storage of conversations, prompts, results, and execution metadata.
• GIN indexes on JSONB for fast vector and text queries. -
Observability, Security, and Deployment
• Docker Compose with isolated networks for each service.
• Encrypted environment variables and API key rotation. -
Extensibility and Best Practices
• Template for adding new commands and workflows in n8n.
• Project structure that facilitates testing, CI/CD, and horizontal scaling.
3- System Architecture
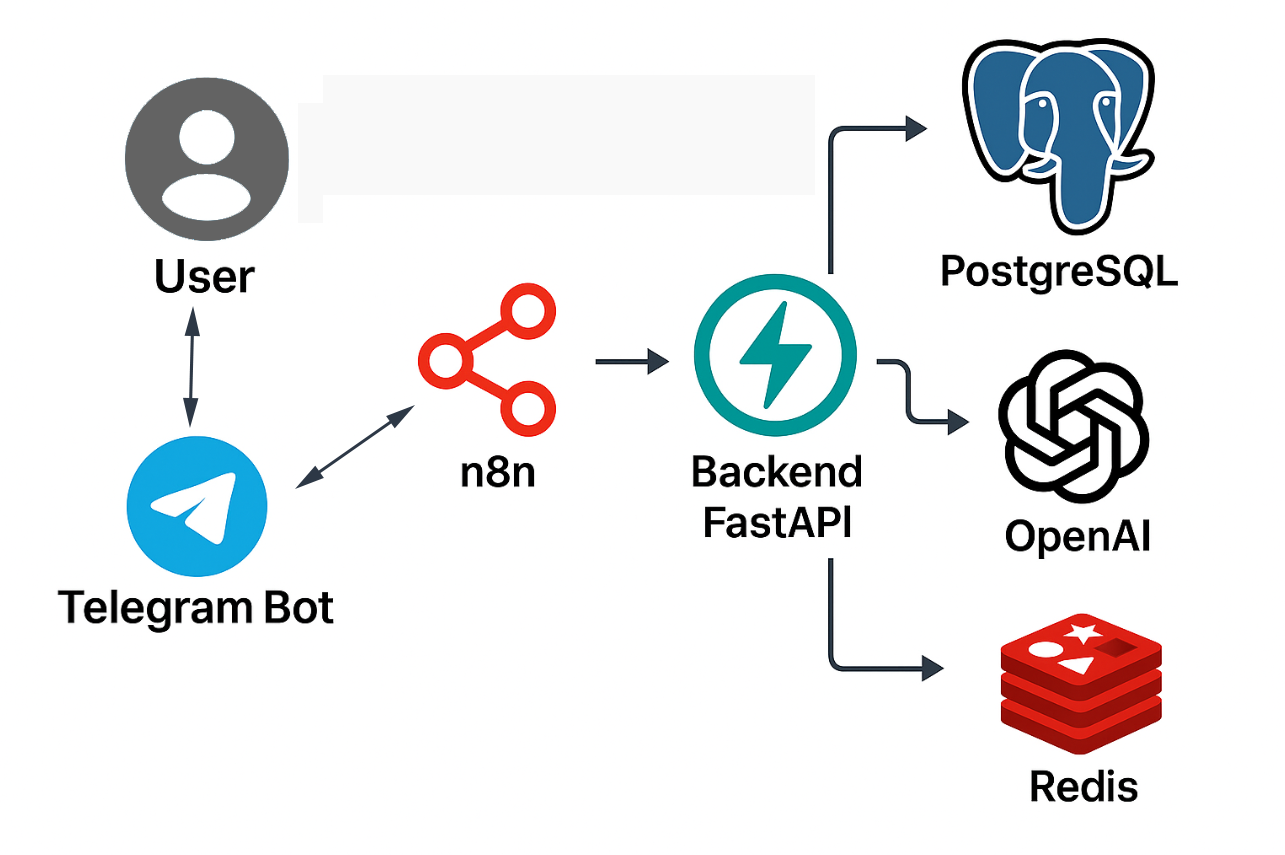
This AI personal assistant is based on a modular, flexible architecture that is easily integrable with other platforms. The main flow is shown below:
-
Telegram Bot
User entry point. From here, commands such as/summarize,/translate, or queries to the history are sent. -
n8n (Orchestrator)
Receives the message, interprets it, and decides which action to execute. It is also capable of enriching the message with additional context (for example, attaching a document or indicating if it is urgent). -
FastAPI (Backend)
Executes the business logic. Each type of task (summarizing, translating, classifying, querying history…) is encapsulated in a well-defined endpoint. Additionally, it maintains traceability of requests and results. -
OpenAI (GPT-4o-mini)
Natural language processing: summaries, translations, semantic classification, etc. -
PostgreSQL
Database that stores each entry, the generated result, the type of task, and the time. It also allows for subsequent queries (“What did I translate on Tuesday?”). -
Redis (optional)
Used to cache recent or frequent responses and optimize overall performance.
4- Backend Components
The backend is built with FastAPI and organizes all business logic and connections with external and internal services. Below are its key components:
📡 Main REST Endpoints
GET /api/v1/status: Checks if the backend is operational.POST /api/v1/process: Receives a request with a task (summarize,translate,classify) and the text to process.POST /api/v1/query: Allows querying the database about the user’s past tasks (for example, “What did I translate this week?”).
These endpoints are designed to be easily tested with tools like Postman, curl, or from n8n via HTTP Request.
🤖 AI Services
Each task (summary, translation, classification) is decoupled into independent functions. Each one is responsible for building a specific prompt and making the call to OpenAI.
Example for the summarize task:
prompt = f"Summarize in English the following text in a maximum of 3 sentences:\n\n{texto}"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=300,
temperature=0.5,
)
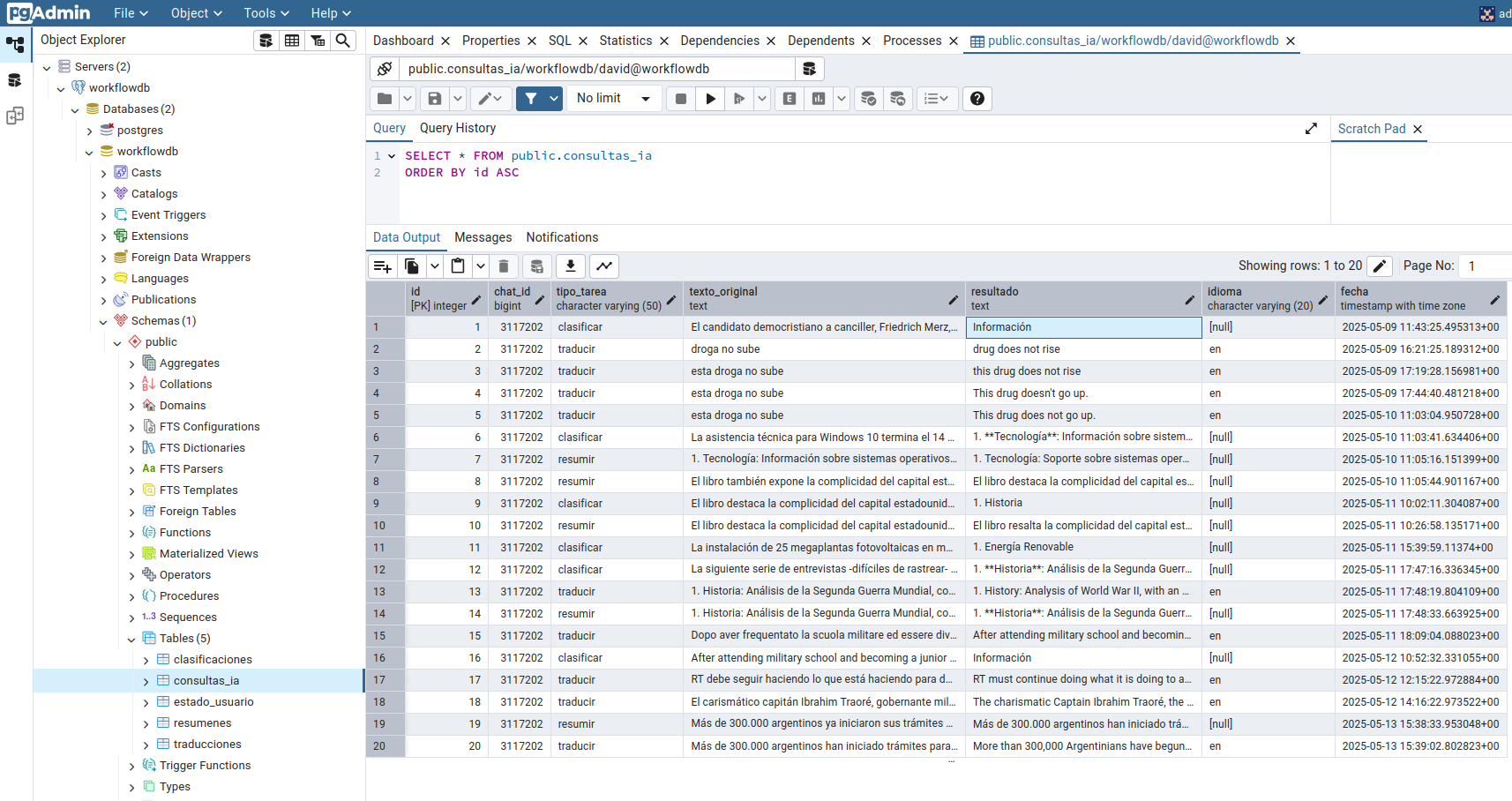
🗃️ Persistence in PostgreSQL
Each processed task is stored in a table called consultas_ia to maintain a history and allow for later queries. The table includes the following columns:
-
id: unique identifier
-
chat_id: user ID
-
type: type of task (summary, translation, classification)
-
original_text: submitted text
-
result: generated response
-
date: date and time of the query
This structure allows functionalities such as user history, auditability, or later analysis.
⚡ Cache with Redis
To speed up responses and avoid redundant calls to OpenAI, Redis is used as a cache layer. A hash key is generated from the text and task type, and if it has already been processed, the response is served instantly.
cache_key = f"{task}:{hashlib.sha256(texto.encode()).hexdigest()}"
If a user requests to translate the same text twice, the first time it takes ~2 seconds (OpenAI API) and the next time less than 50 ms (Redis).
🚨 Error Handling
The backend is prepared to manage failures such as:
-
Delays or errors from OpenAI
-
Loss of connectivity
-
Malformed requests
Retries of up to 3 times are implemented, and a clear message is returned to the user, for example:
“The AI service took too long to respond, please try again later.”
🔐 Security
-
All calls to the backend require an API Key included in the HTTP header (
x-api-key), which is defined in the.envfile and is never exposed publicly. -
The Telegram bot token is also managed as an environment variable.
-
Traffic is conducted over HTTPS if exposed publicly (for example, with ngrok) or in production environments with SSL certificates.
-
These measures ensure privacy and protection against unauthorized access.
5- Flow in n8n (Automation)
What is n8n?
n8n is an open-source visual automation platform that allows connecting services and building workflows without writing code, through nodes that are configured graphically. It is similar to tools like Zapier or Node-RED, but much more flexible and self-hostable.
In this project, I used n8n to manage the interaction logic between Telegram, the backend, and the user, without having to write custom scripts for each step. This allowed me to iterate very quickly and adjust the flows without the need for redeployment.
Structure of the main flow
When a message from Telegram arrives, the flow follows these steps:
-
📩 Telegram Trigger
Captures each incoming message from the user. -
🧾 Function Node: extract command and text
Here, the command (/resumir,/traducir, etc.) is separated from the rest of the message.
This allows the flow to know what type of task the user wants to execute. -
🔍 HTTP Request Node: check status
A call is made to the/api/v1/estadoendpoint of the backend to know if everything is operational or if there is prior information about the user in the database.POST http://backend:8000/api/v1/estado Headers: { "x-api-key": "**********" } -
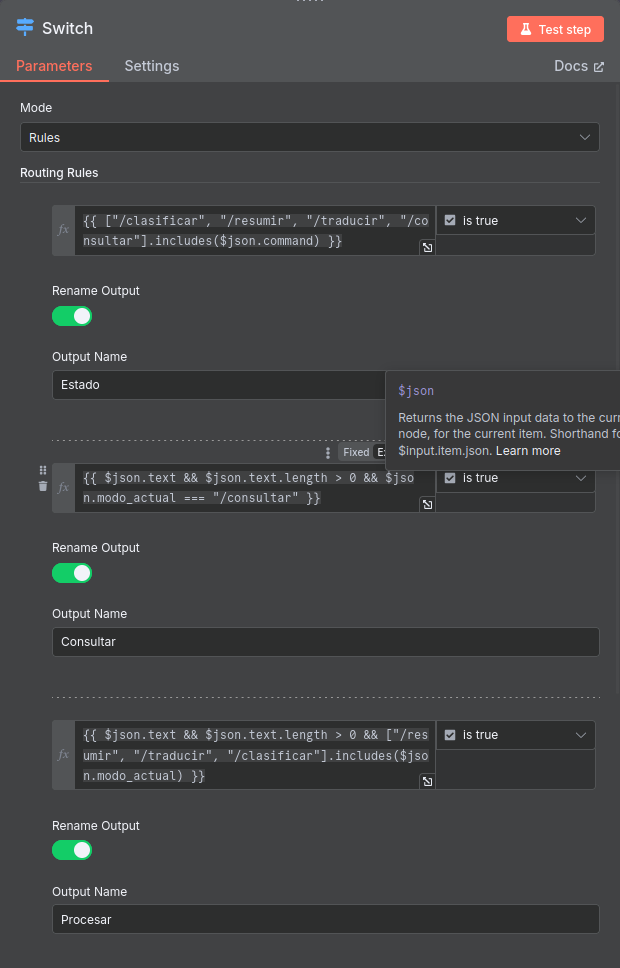
🔀 Switch Node: decide what to do
Depending on the detected command:
-
If it is
/resumir,/traducir, or/clasificar, it branches to the node that calls the/procesarendpoint. -
If it is
/consultar, it goes to the endpoint/consultar. -
If there is no command, the user’s mode is analyzed and action is taken accordingly.
Example of rules in the Switch:
-
msg.command == "/resumir"→ Branch: Process -
msg.command == "/consultar"→ Branch: Consult -
msg.command == undefined && context.mode == "clasificar"→ Branch: Free text
- 🌐 HTTP Request Node: process task
Depending on the branch, this node connects to
/api/v1/procesaror/api/v1/consultarsending the user’s data.
POST http://backend:8000/api/v1/procesar
Body: {
"task": "summarize",
"input": {
"text": "Text that the user wrote"
}
}
Headers: { "x-api-key": "**********" }

- 📨 Telegram Send Message: respond to the user The user is responded to with the result. In some cases, I add interactive buttons (inline keyboard) so that the user can, for example, repeat the task, consult something else, or translate the same text.
Personal Comment
Thanks to n8n, all this logic was built declaratively. A non-technical developer could understand the flow simply by reading the names of the nodes: “Telegram Trigger,” “Extract Command,” “Process HTTP Request,” “Send Response,” etc.
Personally, I found n8n very useful for quickly testing different conversation paths without deploying code each time. It allowed me to iterate swiftly, detect conceptual errors in the flows, and add new features in minutes.
6- Deployment and Monitoring
🚀 Deployment Environment
The project runs in a Dockerized environment to ensure portability and ease of configuration. I use docker-compose to bring up all the necessary services:
- FastAPI backend
- n8n
- PostgreSQL
- Redis
- pgAdmin
The docker-compose.yml file defines each service, their networks, and volumes. Sensitive variables such as API keys or tokens are stored in a .env file and are not pushed to the repository.
This allows bringing up the entire system with a single command:
docker compose up -d
🔐 Security and Best Practices
- Secrets (such as
API_KEY,TELEGRAM_TOKEN) are stored in environment variables and are never exposed in the source code. - In production, traffic is encrypted with HTTPS using a reverse proxy or tools like ngrok for quick testing.
- Only what is necessary is exposed externally: for example, n8n listens on a restricted subdomain, and the backend communicates with it over the internal Docker network.
📊 Monitoring
To observe system behavior and anticipate errors or bottlenecks, the following is used:
- Grafana + Prometheus or Loki (optional): to visualize metrics, logs, and performance traces.
- Structured logs: the backend emits logs in JSON format, which can be processed by tools like Loki.
- n8n UI: provides a clear view of the status of flows, execution history, errors, and automatic retries.
Example of a useful dashboard:
- Number of requests by type (
summary,translation,classification) - Average response time per task
- Percentage of responses served from Redis vs OpenAI
🧪 Testing and Maintenance
- An endpoint
/statusis included to check if the backend is functioning correctly. - n8n workflows can be easily cloned, exported, or versioned in JSON.
- Redis allows observation of which tasks are cached, and PostgreSQL stores the entire query history, facilitating future audits or analyses.
This setup allows for a lightweight and efficient deployment, easily replicable in other environments (cloud, VPS, local).
6- Result: Usage Examples
Below are some real scenarios where the assistant has proven to be useful. These cases not only illustrate what it can do but also how it can be integrated into the daily life of anyone who handles a lot of information.
📬 Example 1: Summarizing a long email
I receive an extensive email of three paragraphs with details about an upcoming meeting, pending tasks, and links. Instead of reading everything, I copy the text and write to the bot:
`/summarize` Hello team, as we discussed in the last meeting, the session with marketing will be on Tuesday. We need to prepare the materials and confirm attendance. The technical roadmap will also be reviewed, so please be ready to share progress...
The bot correctly interprets my intention and responds:
Your latest translations:
- 2025-05-08 – Technical fragment on system architecture
- 2025-05-06 – Client confirmation email
- 2025-05-05 – Product webpage (in English)
🏷️ Example 2: Classifying a request
A colleague forwards me this message:
“The new update causes the app to crash constantly when opening PDF files.”
I pass it to the bot with:
`/classify` The new update causes the app to constantly crash when opening PDF files.
And I receive:
Classification:
Category: Bug/Error
Component: PDF Viewer
Sentiment: Negative
Urgency: High
Suggested action: Escalate to development
It automatically provided me with the necessary context to prioritize this incident without wasting time.
🌍 Example 3: Technical Translation
I am reading technical documentation in English and want to understand a fragment well. I send:
`/translate The system employs a multi-tier architecture with redundant failover mechanisms to ensure availability.
The bot returns:
Translation:
The system employs a multi-tier architecture with redundant failover mechanisms to ensure availability.
The translation maintains the technical tone and is completely understandable.
📑 Example 4: Intelligent Query of History
I want to know what tasks I’ve done recently, so I write:
Show me my latest translations
The bot correctly interprets my intention and responds:
Your latest translations:
- 2025-05-08 – Technical fragment on system architecture
- 2025-05-06 – Client confirmation email
- 2025-05-05 – Product webpage (in English)
It also adds a button: See more, to continue browsing the history.
These examples demonstrate that the assistant works with natural language, responds quickly, and adds value in everyday tasks such as reading emails, understanding documentation, or prioritizing incidents.
7- Challenges Encountered and Learnings
Building this assistant involved integrating multiple components (Telegram, n8n, FastAPI, Redis, OpenAI, PostgreSQL) and ensuring they communicated reliably and efficiently. Here were some of the main challenges and learnings during development:
🔄 Synchronization between n8n and the backend
One of the first challenges was to correctly handle the chat_id from Telegram for each message. It was crucial for n8n to extract and transmit this information to the backend so that responses were personalized and coherent. This forced me to understand well how the structure of messages in Telegram works and how to maintain context throughout the flow.
⚡ Latency Optimization
In the first version, all tasks were sent directly to the OpenAI API, which sometimes resulted in response times of up to 10 seconds.
By introducing Redis as a cache, optimizing the prompts, and limiting the maximum output tokens, I was able to ensure that most responses arrived in less than 2 seconds, drastically improving the user experience.
🔐 Secure Token Management
I learned to use .env files and environment variables to securely handle project secrets (such as the TELEGRAM_TOKEN or the API_KEY from OpenAI).
This approach not only protects sensitive data but also facilitates the portability of the project between environments (development, production, etc.).
📚 Community and Documentation
I had moments of blockage, especially when setting up certain nodes in n8n or properly structuring the endpoints in FastAPI. The official FastAPI documentation, n8n forums, and various discussions on GitHub helped me resolve doubts and understand best practices.
This process reinforced my ability to research and rely on the community when something didn’t work as expected.
✅ Validation and Testing
I conducted unit tests simulating responses from OpenAI to ensure that the system handled timeouts and errors such as RateLimitError or InvalidRequestError correctly.
I also did informal tests with friends and colleagues: I asked them to use the bot on Telegram and give me feedback. Thanks to their observations, I adjusted the length of the responses, improved the interactive buttons, and refined the logic of the history.
This project not only allowed me to apply my technical knowledge but also to sharpen my design criteria, improve user experience, and strengthen my mastery of key tools like FastAPI, n8n, and Redis.
8- Conclusion
This project demonstrates the enormous potential of combining automation with artificial intelligence. Nowadays, it is entirely possible to build your own personal assistant that summarizes texts, translates technical fragments, or classifies messages, all integrated with the tools you already use, like Telegram.
Since I started using this system, tasks that used to take me several minutes (like reading long emails, prioritizing incidents, or translating documentation) are now resolved in seconds.
Receiving a clear summary or a structured response directly on my phone has radically changed the way I manage daily information.
🧠 Are you interested in building something similar or adapting it to your workflow?
👉 You can check the complete code of the project here: 🔗 View repository on GitHub
Thanks for reading this far!!! 🙌
If you have questions, suggestions, or want to share how you would apply something similar in your environment, I would be happy to read your comments or messages!