Our objective is to obtain information about Groceries in the UK. To do this we searched the web https://find-and-update.company-information.service.gov.uk/ and extract the name of the company, the owner’s name and address.
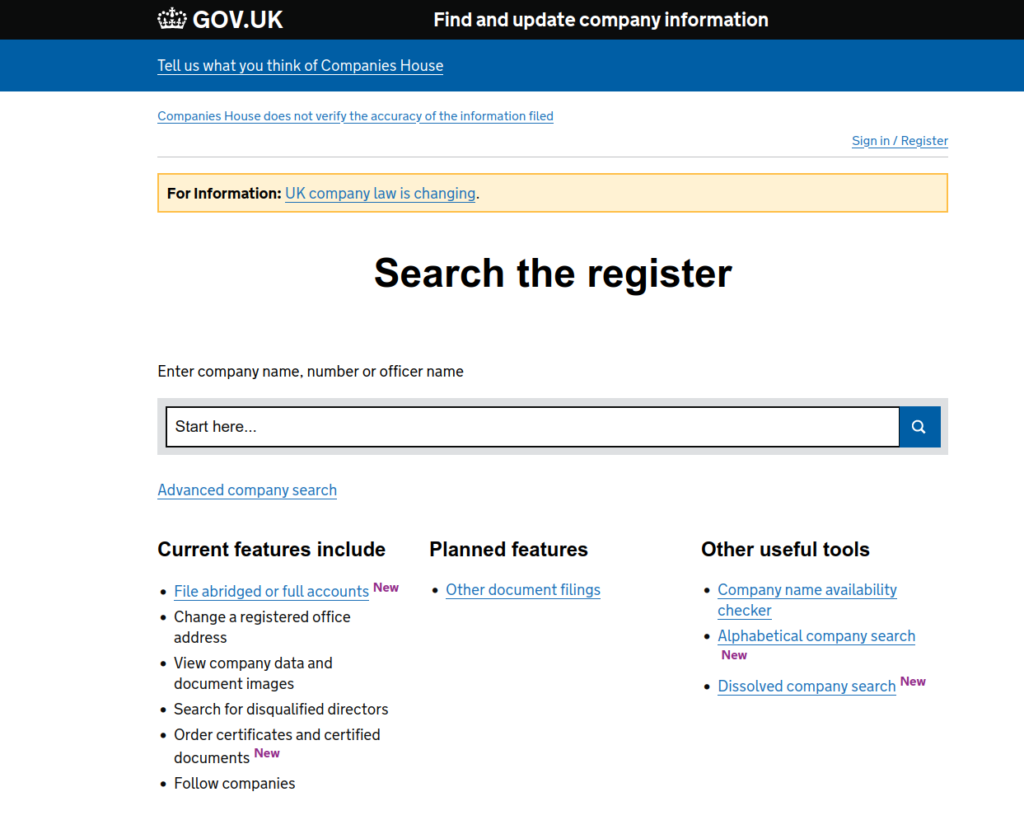
I use Scrapy to do this.
The general structure of our algorithm is as follows:
import json
import urllib
import scrapy
from scrapy.selector import Selector
class GroceriesSpider(scrapy.Spider):
...............................
..............................
'q': 'groceries',
#'id': '',
'page': ''
}
def start_requests(self):
..................................
..................................
yield scrapy.Request(next_page, callback = self.parse_list)
def parse_list(self, response):
...........................................
...........................................
...........................................
...........................................
...........................................
yield response.follow(
url=next_page,
dont_filter=True,
callback=self.parse
)
def parse(self,response):
...........................................
...........................................
...........................................
...........................................
...........................................
...........................................
...........................................
yield lista
# Save lista in a .json
...........................................
...........................................
We have to browse the web through different links until we get the information of each grocery.
– GroceriesSpider Class
First we create the main class where we will put the different functions. The variables will be the address of the main page and a dictionary that will store the word we want to search for ‘groceries’, and the page where it is found.
class GroceriesSpider(scrapy.Spider):
name = 'groceries'
#allowed_domains = ['https://find-and-update.company-information.service.gov.uk/']
base_url = 'https://find-and-update.company-information.service.gov.uk'
params = {
'q': 'groceries',
#'id': '',
'page': ''
}
......................................................................
......................................................................
– start_requests() function
We create a function to obtain the web address where we will make the request, taking into account that for the groceries we have 20 pages, we will go through each one.
def start_requests(self): #--------- Pagination (...?q=groceries&page=2)-------
for i in range(1,21):
self.params['page'] = i
next_page = self.base_url + '/search/companies?' + urllib.parse.urlencode(self.params)
yield scrapy.Request(next_page, callback = self.parse_list)
– parse_list() function
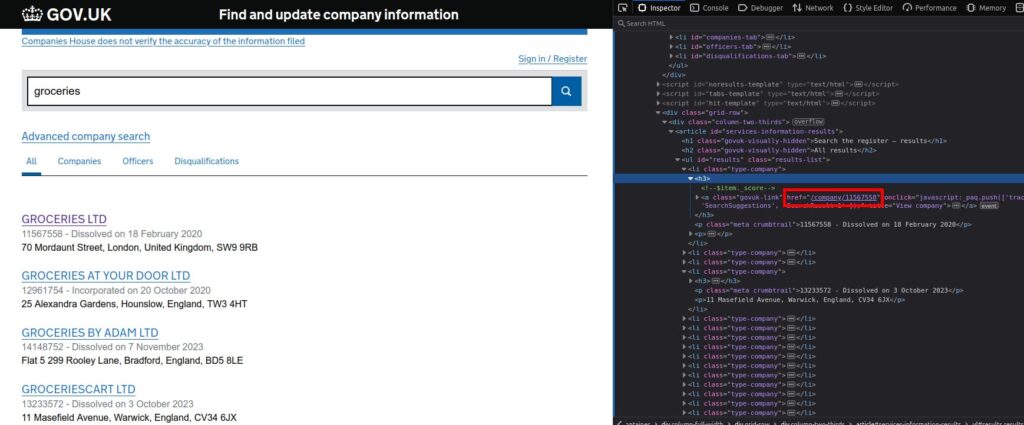
Once we have the web address of a page and we have entered, we copy its HTML code to a file and then read it. Then the algorithm extracts the URL and we access the information of each grocerie:
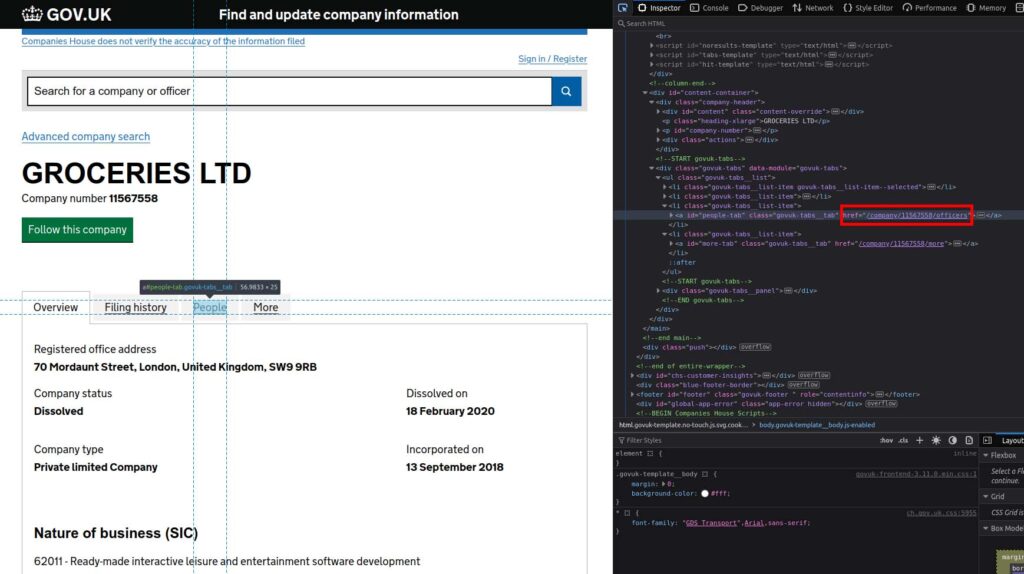
The relevant information we want to extract is located in the People tab, which if you look at the source code corresponds to /officers/`. Save and pass the address to the next function.
This is the algorithm for parse_list function:
def parse_list(self, response):
# write HTML response to local file
with open('res.html', 'w') as f:
f.write(response.text)
# local HTML content
content = ''
# load local HTML file to extract data
with open('res.html', 'r') as f:
for line in f.read():
content += line
#print(content)
# init scrapy selector
res = Selector(text=content)
#print(res)
for card in response.css('.type-company'):
link = card.css('a::attr(href)').get()
# titulo = card.css('a::text').get().strip()
id = link.split('/')[-1]
# print("TITLULO: ", titulo)
# print("LINK: ", link)
print("ID: ", id)
#https://find-and-update.company-information.service.gov.uk/company/SC612546/officers/
next_page = self.base_url + '/company/' + str(id) + '/officers/'
print(next_page)
yield response.follow(
url=next_page,
dont_filter=True,
callback=self.parse
)
– parse() function
Finally we access the people tag. And as we did before we save the HTML to read it later and access the information we want:
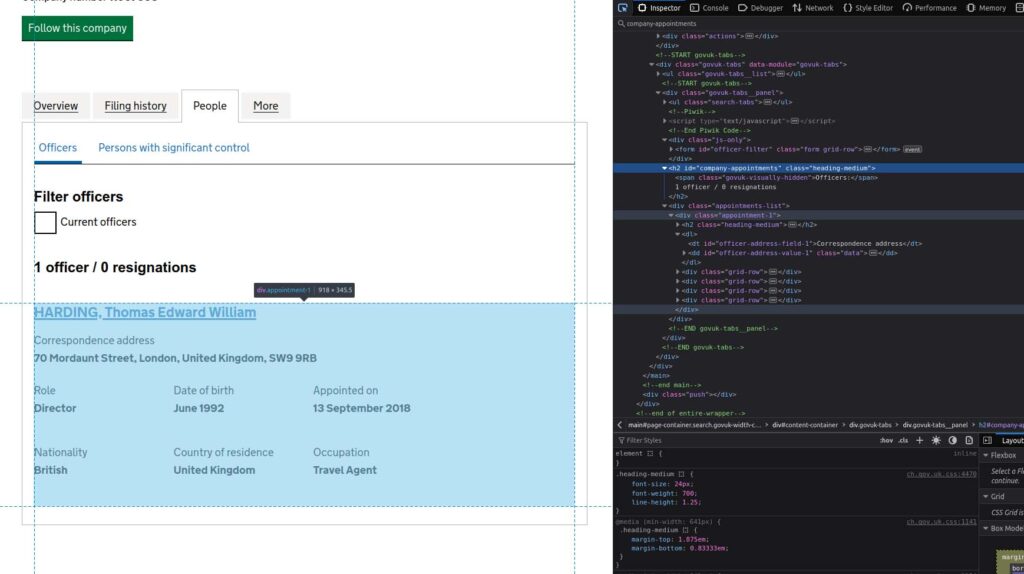
This is the algorithm for parse function:
def parse(self,response):
# write HTML response to local file
with open('res2.html', 'w') as f:
f.write(response.text)
# local HTML content
content = ''
# load local HTML file to extract data
with open('res2.html', 'r') as f:
for line in f.read():
content += line
print(content)
# init scrapy selector
res = Selector(text=content)
print("RRREEESSSS :", res)
lista = {
}
print("\n")
resignations = str(response.css('#company-appointments::text').extract()).strip().split(' ')[-6]
empresa = response.css('.heading-xlarge::text').get().strip()
print("RESIGNATIONS: ", resignations)
print("EMPRESA: ", empresa)
lista['company'] = empresa
for i in response.css('div[class^="appointment-"]'):
role = i.css('div dd[id^="officer-role-"]')
for j in role:
puesto = j.css('::text').get().strip()
try:
active= i.css('span[id^="officer-status-tag-"]::text').get().strip()
except:
pass
if (puesto == 'Director' and resignations == '0') or (puesto == 'Director' and resignations != '0' and active == 'Active'):# and (active is None or active == 'Active'):
nombre = i.css('a::text').get().strip()
address = i.css('dd[id^="officer-address-value-"]::text').get().strip()
print("PUESTO: ", puesto)
print("NOMBRE: ", nombre)
print("ADDRESS: ", address)
lista['name'] = nombre
lista['address'] = address
yield lista
We create a list where we store the name of the company, the name of the officers and the address. Group by company:
{
"GROCERIES AND DELIVERY LIMITED": [
{
"company": "GROCERIES AND DELIVERY LIMITED",
"name": "SONG, Feifei",
"address": "102 Gervase Road 102, Sheffield, United Kingdom, S8 7PS"
}
],
"AMERICAN GROCERIES ONLINE LIMITED": [
{
"company": "AMERICAN GROCERIES ONLINE LIMITED",
"name": "MILLER, Graeme",
"address": "1 Lamsey Cottages, Dagnall Road, Little Gaddesden, Berkhamsted, England, HP4 1QS"
}
],
"CHELMSFORD MEAT AND GROCERIES LTD": [
{
"company": "CHELMSFORD MEAT AND GROCERIES LTD",
"name": "AHMAD, Saif Ur-Rehman",
"address": "94 Byron Road, Chelmsford, United Kingdom, CM2 6HJ"
}
],
"DIVINE GROCERIES LTD": [
{
"company": "DIVINE GROCERIES LTD",
"name": "NNAJIOBI, Anyachonkeya Lovina",
"address": "Unit Pr01 & Pr02, Gorton District Centre, Garratt Way, Manchester, England, M18 8LD"
}
],
"FOOD GROCERIES LIMITED": [
{
"company": "FOOD GROCERIES LIMITED",
"name": "MONTRIMAS, Virginijus",
"address": "11 Market House, Harlow, England, CM20 1BL"
}
],
"GOLD COAST GROCERIES LTD": [
{
"company": "GOLD COAST GROCERIES LTD",
"name": "ADOM-KUMI, Patience",
"address": "49 Castle Street, Salisbury, England, SP1 3SP"
}
],
"HYTHE GROCERIES LTD": [
{
"company": "HYTHE GROCERIES LTD",
"name": "AMEEN, Talaat Asaad",
"address": "123 Hythe Hill, Colchester, England, CO1 2NP"
}
],
"LIMEHOUSE GROCERIES LTD": [
{
"company": "LIMEHOUSE GROCERIES LTD",
"name": "RAHMAN, Zillur",
"address": "Railway Arch, 242 Ratcliffe Lane, London, United Kingdom, E14 7JE"
}
],
"MILE END GROCERIES LIMITED": [
{
"company": "MILE END GROCERIES LIMITED",
"name": "AHMED, Wadud",
"address": "122 Stamford Road, Dagenham, Essex, England, RM9 4ES"
}
],
"OCEAN FISHERIES & GROCERIES LTD": [
{
"company": "OCEAN FISHERIES & GROCERIES LTD",
"name": "MAHMOOD, Hawkar Abdulrahman",
"address": "38-40, Watling Avenue, Edgware, United Kingdom, HA8 0LR"
}
],
"PEEVI GROCERIES LTD": [
{
"company": "PEEVI GROCERIES LTD",
"name": "BROWN, Vivian",
"address": "3 Cambrai Court, Canterbury, England, CT1 1AW"
}
],
..............................................................................
..............................................................................
..............................................................................
..............................................................................
..............................................................................
"CAPITAL GROCERIES LIMITED": [
{
"company": "CAPITAL GROCERIES LIMITED",
"name": "AHMADZAI, Mohammed",
"address": "277 Eversholt Street, London, England, NW1 1BA"
}
],
"SIERRA LEONE GROCERIES LIMITED": [
{
"company": "SIERRA LEONE GROCERIES LIMITED",
"name": "KAMARA, Janaba Sadiatu",
"address": "56 Granville Arcade, Coldharbour Lane, London, United Kingdom, SW9 8PS"
}
],
"RAJ FOOD, WINES AND GROCERIES LTD": [
{
"company": "RAJ FOOD, WINES AND GROCERIES LTD",
"name": "ALWADI, Raj Singh",
"address": "Flat 13, Shawfield Court, 29 Church Road, West Drayton, Middlesex, United Kingdom, UB7 7QD"
}
],
"SEVEN STARS FOODS & GROCERIES LIMITED": [
{
"company": "SEVEN STARS FOODS & GROCERIES LIMITED",
"name": "MICHEAL, Yosef",
"address": "14 Green Lane, Thornton Heath, United Kingdom, CR7 8BA"
}
]
}