📝 Introduction
Managing clients, invoices, and reports is crucial for businesses of any size. AI Client Agent MCP is an advanced backend system that tackles this need by integrating a relational database with AI-driven automation. It’s designed to be operated by an AI agent (or programmatically via API), meaning you can interact with it through natural language or scripted commands. The goal is to automate client management, invoicing, and reporting tasks that traditionally require manual effort, by leveraging artificial intelligence and modern backend technologies.
In a nutshell, AI Client Agent MCP provides a PostgreSQL-powered data store for clients, invoices, managers, etc., and exposes a suite of functions (or “tools”) to query and manipulate this data. An AI agent layer sits on top, capable of understanding high-level requests (e.g. “Show all pending invoices”) and invoking the appropriate tool functions under the hood. The result is a system where routine administrative tasks can be handled through a conversational assistant or automated scripts, producing professional results like detailed reports and updates without human micromanagement.
Key Features and Capabilities:
-
🗃️ Relational Database Backbone: At its core is a PostgreSQL 15 database with multiple related tables for clients, invoices, managers, and reports GitHub. This ensures data is stored securely with proper relationships (clients to invoices, etc.), enabling complex queries and maintaining data integrity.
-
🧠 AI-Driven Reporting: The system can generate detailed business reports automatically. The AI agent queries and cross-references data across entities and produces a polished HTML report with summaries, trends, and recommendations. These reports are even sent out via email to authorized managers, providing decision-makers with timely insights without manual report compilation.
-
🕹️ MCP Agent Architecture: “MCP” stands for Model Constext Protocol – a nod to the centralized AI agent orchestrating the system. Using the FastMCP framework, the project registers various tools (functions) that the agent can call to fulfill user requests. This architecture allows natural language interfaces to trigger precise backend operations safely.
-
🛠️ Full CRUD Functionality: The platform isn’t limited to read-only queries – it supports creating and updating records as well. There are dedicated tools for creating, reading, updating, and deleting clients and invoices. For example, one tool
create_client(name, city, email)adds a new client, whileupdate_invoice(...)can modify invoice details. All inputs are validated (using Pydantic models) to maintain data quality and consistency. -
📦 Containerized Deployment: To simplify setup and deployment, everything is containerized with Docker. A Docker Compose configuration orchestrates the app, PostgreSQL database, and a pgAdmin service for DB administration. This means you can get the entire stack running with a single command (
docker compose up) and be confident it will run the same in any environment – great for testing, development, or production scaling. -
🧰 Tech Stack Overview: The backend is implemented in Python 3.11 and makes heavy use of asynchronous programming for efficiency. It utilizes FastAPI (via the FastMCP library) to run an async server and handle requests, and asyncpg for high-performance asynchronous database access. Data models and validation are handled with Pydantic, ensuring that, for instance, an invoice’s schema or a client’s email field are correct. The project also integrates the OpenAI API for natural language processing and content generation, and uses Matplotlib to create charts for reports. On the DevOps side, tools like Black, Ruff, PyTest, and Pre-commit hooks are configured to maintain code quality and reliability.
If you want a more detailed analysis of the Backend, you can check the README.md in the project’s Github repository.
🧭 Architecture and Internal Workflow
Internally, AI Client Agent MCP follows a layered architecture to separate concerns and enhance maintainability:
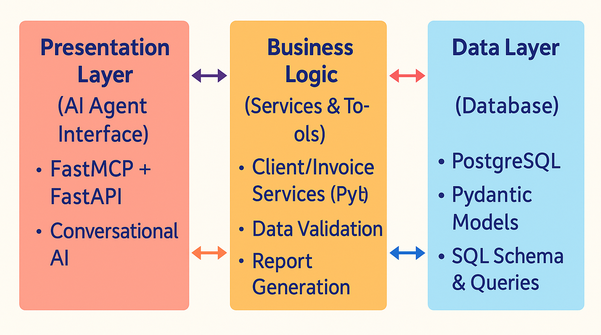
🎙️ Presentation Layer (AI Agent Interface): This is the entry point through which users (or external AI assistants) interact. The system runs a FastAPI-based server that uses Server-Sent Events (SSE) to maintain a live connection with a client (for example, a custom UI or an AI coding assistant like Cursor IDE). The AI agent, powered by FastMCP, “listens” for user queries. FastMCP is a framework that allows defining tools (functions) and automatically handles routing calls to those tools. Each tool is annotated with @mcp.tool and registered with a central MCP instance on startup. When a request comes in (say via a natural language prompt), the agent can decide which tool to invoke and does so through the MCP layer. The SSE connection means the agent can stream back responses, which is useful if the AI is generating a lengthy report or needs to provide intermediate feedback.
🧠 Business Logic Layer (Services & Tools): This layer contains the actual logic for handling operations. It includes service modules (for clients, invoices, reports) and the tool functions that wrap those services. For example, there’s a client_service and invoice_service module that contain functions like create_client or get_all_invoices which interact with the database. The tool functions in turn call these service functions. Notably, the services are written to accept an optional database connection parameter – a form of dependency injection that allows greater flexibility and testability. In fact, the codebase was refactored to incorporate this pattern for the client and invoice services. This means during normal operation, a service can obtain its own database connection, but during testing, a pre-started transaction or a dummy connection can be passed in, enabling isolation. (We’ll touch more on testing later.) The business logic layer also handles things like data validation (using Pydantic models to enforce types and formats) and assembling data for reports.
One of the standout tools in this layer is generate_report. It pulls together functionality from all parts of the system: checking user permissions, gathering data, calling the AI, and dispatching an email. When generate_report is invoked, it will:
-
Verify the provided manager name/email corresponds to an authorized manager in the database (only managers in the
managerstable are allowed to receive reports). -
Fetch all relevant invoices, either for a specific client or globally, optionally filtered by a time period.
-
Use the OpenAI API to generate a textual HTML report. The tool builds a prompt that includes an instruction (e.g. “You are a financial analyst, prepare a detailed report…”) along with the raw data (invoice records) embedded in the prompt. The AI then returns a nicely formatted report in HTML, which includes sections like an executive summary, analysis of totals, trends, and recommendations.
-
Generate a visualization: the code can produce a chart (currently a simple bar chart of invoice statuses: paid, pending, canceled) using Matplotlib, which can be embedded in the report. This adds a visual element to the analysis.
-
Clean and sanitize the AI-generated HTML. This is an interesting challenge – since the content comes from an LLM, it might include extraneous formatting. The system uses the Bleach library to strip out any unwanted HTML/CSS and ensure the output is safe and well-formed.
-
Email the final report to the manager’s email address. The project uses Python’s built-in email capabilities (smtplib) configured via environment variables for SMTP host, port, and credentials. The
generate_reporttool assembles an email with the HTML report and sends it out automatically, with the subject line indicating the report context (client name, period, etc.). -
Finally, log the report in the database. Each sent report can be saved (with a timestamp and maybe the content or a link to it) in a
reportstable for auditing and future reference.
All these steps happen behind the scenes in a matter of seconds once an AI agent or user triggers the generate_report function.
🗄️ Data Layer (Database): This layer is a PostgreSQL database that stores all the persistent information. The schema includes tables for clients (with fields like name, city, email), invoices (amount, dates, status, linked to a client), managers (authorized report recipients), and reports (generated reports metadata). The SQL schema is initialized via scripts (for example, create_tables.sql defines the tables and their relationships) and is set up automatically when you run the Docker setup. As the system uses async database calls via asyncpg, it can handle multiple requests concurrently with high performance. By using direct SQL (instead of an ORM), the code exercises fine-grained control over queries, which is great for performance and transparency. The data layer also benefits from Pydantic models on the Python side (defined in backend/models) which mirror the database tables and ensure any data coming in or out meets the expected structure. For example, here our clients table:
To give a clearer picture, let’s walk through a use case scenario combining all layers:
Example: A manager types into the AI assistant, “Give me a detailed report of all completed quotes for client Carolina Padilla and send it to David Salas.” – The AI agent (via the presentation layer) receives this natural language request. It parses the intent: the user wants a detailed, completed-invoices report for client Carolina Padilla, to be sent to manager David Salas. The agent consults its toolset and decides this calls for the
generate_reporttool. It invokesgenerate_report(client_name="Carolina Padilla", period="", manager_name="David Salas", manager_email="[email protected]", report_type="detailed, only completed", api_token="..."). The business logic layer now kicks in: the tool checks that David Salas is an authorized manager in the DB and that Carolina Padilla exists as a client. It gathers all invoices for Carolina Padilla (sinceperiod=""it takes all dates) and filters those with status “paid”. With that data, it builds the prompt and calls OpenAI to generate the report content. The returned HTML report might say “Executive Summary: Client Carolina Padilla has X completed quotes totaling Y amount…” etc., including any trends or recommendations the AI finds. The code attaches a bar chart image showing how many invoices are paid vs pending, etc., for visual flair. The completed report is emailed to David’s address (which was on file in the managers table). David receives an email with a professional-looking report in HTML format, complete with tables and charts, within perhaps a minute of the request – all automatically. Meanwhile, the interaction could be conversational: the AI agent could respond back in the chat interface with a confirmation like “✓ I’ve sent a detailed report to David Salas.” The entire flow required no human data crunching – it was the AI agent orchestrating database queries and using the reporting toolset to deliver value.
🧩 Notable Technical Challenges and Decisions
Building AI Client Agent MCP involved addressing several interesting technical challenges:
-
🔌 Agent Orchestration & Communication: Choosing FastMCP as the backbone allowed us to easily register tool functions that an AI agent can call. One challenge was enabling a smooth communication channel between the AI (which could be running in an IDE plugin or a web UI) and the backend. We opted for Server-Sent Events for pushing real-time updates from the server to the client, which is simpler than websockets for our use case yet effective for streaming AI responses. Ensuring that each tool execution is stateless (the FastMCP is configured in stateless HTTP mode) means each request is handled independently, which simplifies scaling and avoids cross-request side effects.
-
🔄 Asynchronous, Scalable Design: The entire stack is asynchronous, from the web server down to the database calls. This was a deliberate decision to allow high concurrency (multiple requests or tool calls can be in flight without blocking each other). We used
asyncpgfor database operations, which is a performant async PostgreSQL driver, instead of a traditional ORM. One complexity with async code is managing database connections and transactions. We implemented a pattern where service functions can accept an external connection or manage their own. This dependency injection approach required careful design but paid off in making the code more testable and flexible. -
🧪 Dependency Injection for Testability: To ensure reliability, we wrote extensive tests (both unit tests and integration tests). A highlight here is how we manage database state during tests. We did transactional integration testing, meaning each test runs inside a database transaction that is rolled back at the end. This provides a clean slate for each test run. The
conftest.pyfixture shows this pattern: it opens a connection, starts a transaction (conn.transaction()), yields control to the test, then rolls back any changes on teardown. This way, tests can create and modify database entries freely and we guarantee those changes won’t leak into other tests (or the real database). Combined with the dependency injection in services (passing the test connection into the functions under test), we achieved isolated, repeatable tests without needing to spin up a new DB for each test case. -
🛡️ Data Validation and Security: Data integrity and security are paramount in an automated system. We use Pydantic models to validate inputs and outputs for all major operations, catching issues like invalid email formats or missing required fields early. On the security front, certain operations are restricted – for example, the
generate_reporttool requires a valid API token and will refuse to run if the token is missing or incorrect. This is to prevent unauthorized triggering of potentially sensitive operations. Moreover, the system checks that any email recipient of a report is in the managers table (whitelisted) and included explicitly in the request. This avoids scenarios where an AI might attempt to email data to an arbitrary address. All email sends and report generations are logged, and the report itself notes the recipient, adding a layer of accountability. -
🧬 Handling AI Output (LLM Integration): Incorporating an AI (OpenAI’s GPT model) for generating reports introduced its own set of decisions. We had to construct effective prompts that provide the model with all necessary data (invoice details) and clear instructions on format. The model is asked to output professional HTML, which saves us from manually formatting the report. However, models can be unpredictable in format, so we implemented a cleaning step: using regex and the Bleach library to sanitize the HTML. This strips out any extraneous code blocks or styles that the model might include and ensures only safe HTML tags remain. The result is that we can trust the HTML content that gets emailed out. This approach showcased how an LLM can be harnessed to produce practical business documents when guided properly.
-
📋 Logging and Monitoring: The system uses a custom logging setup (see
backend/core/logging.py) to record events. At startup the server logs environment info and writes logs to a file (inside app_logs/). Each tool function can log important events (like unauthorized access attempts, errors, etc.). This was important for debugging, especially since an AI-driven system can be complex – having a trail of what the agent did and any issues encountered helps in fine-tuning and troubleshooting. -
🧰 Continuous Integration and Code Quality: To maintain high code quality, the project integrates several developer tools. We use Black for automatic code formatting and Ruff along with Flake8-bugbear for linting, catching common errors or bad practices. MyPy is employed for static type checking, which is quite helpful in a codebase that involves database interactions and external APIs – it catches mismatches and mistakes before runtime. Additionally, a pre-commit configuration is set up, so that these linters and formatters run automatically on each commit, preventing bad code from ever being committed. The testing setup is wired into a CI workflow (coverage reports, etc.), ensuring that as new features are added, they don’t break existing functionality.
📈 Applications and Future Roadmap
AI Client Agent MCP is especially useful for organizations looking to automate their back-office operations. It can serve as the backend for an intelligent CRM (Customer Relationship Management) system or as the brain behind a virtual finance assistant. Some practical applications include:
-
📑 Automated Report Generation: Finance or sales teams can request reports (monthly sales, outstanding invoices, client summaries) via a chat interface and get polished reports ready to share.
-
🔍 Intelligent Data Querying: Non-technical staff could ask questions like “How many clients have overdue invoices?” and get answers without writing SQL – the AI agent translates the question into database queries and returns the result.
-
🧾 Streamlined Client Management: New client onboarding or updates can be done through conversational forms. For example, an assistant could ask “What’s the new client’s name and details?” and then call the create_client tool in the backend.
-
🤖 Integration with Chatbots or Voice Assistants: Because the system can be driven by natural language, it could integrate with Slack bots or voice assistants (like Alexa for business) to provide hands-free access to company data (“Alexa, how many invoices were paid last week?”).
The project is open-source (MIT License) and meant to be a foundation that can be extended. Going forward, there are several improvements on the roadmap:
-
Implementing more sophisticated invoice state management (for example, configurable state transitions for invoice status beyond the basic paid/pending).
-
Adding detailed audit logs for all operations, so every change to a client or invoice is recorded (important for compliance in finance).
-
Integrating database migration tools like Alembic, to handle schema changes without rebuilding the entire database.
-
Expanding the AI capabilities – e.g., using analytical libraries (like Pandas or Plotly, which are already in the dependencies) to augment the reports with deeper insights or interactive charts.
-
Potentially incorporating authentication/authorization for a production environment (e.g., securing the FastAPI endpoints with JWT tokens, so that only permitted users or services can connect to the agent). Currently, the assumption is that it runs in a controlled environment, but for a public deployment this would be essential (along with encryption, etc.).
-
Building a front-end interface for those who prefer a GUI over conversational interaction – for instance, a dashboard that internally calls the same MCP tools but through buttons and forms.
In conclusion, AI Client Agent MCP demonstrates how we can combine modern asynchronous backend tech with AI to reduce tedious administrative work. It showcases a modular, tested architecture where an AI agent can safely interact with a database and external systems to carry out complex tasks on behalf of users. From automated emailing of reports to dynamic query handling, the project highlights a path toward smarter enterprise software – where routine tasks are delegated to intelligent agents, and humans can focus on higher-level decision making. With ongoing improvements, this platform could evolve into a powerful smart assistant for business operations, illustrating the practical synergy between AI and backend development in the realm of enterprise automation.