Our objective is to make a summary of the type of restaurant that a tourist or a resident can find in each neighborhood of Berlin. Where to eat American food, German food,…
1 – Import Libraries
from IPython.display import Image
from IPython.core.display import HTML
import pickle
import requests
import folium
import pandas as pd
import numpy as np # library to handle data in a vectorized manner
import shapely.geometry
from geopy.geocoders import Nominatim # module to convert an address into latitude and longitude values
import pyproj
import math
import matplotlib.pyplot as plt
import json
from pandas.io.json import json_normalize # tranform JSON file into a pandas dataframe
# Matplotlib and associated plotting modules
import matplotlib.cm as cm
import matplotlib.colors as colors
# import k-means from clustering stage
from sklearn.cluster import KMeans
from bs4 import BeautifulSoup
2 – Extract Berlin Boroughs info
url = 'https://en.wikipedia.org/wiki/Boroughs_and_neighborhoods_of_Berlin'
source = requests.get(url).text
soup = BeautifulSoup(source)
table_data = soup.find('div', class_='mw-parser-output')
table = table_data.table.tbody
columns = ['Borough', 'Population', 'Area', 'Density']
data = dict({key:[]*len(columns) for key in columns})
for row in table.find_all('tr'):
for i,column in zip(row.find_all('td'),columns):
i = i.text
i = i.replace('\n', '')
data[column].append(i)
df = pd.DataFrame.from_dict(data=data)[columns]
df
Borough
Population
Area
Density
0
Charlottenburg-Wilmersdorf
319,628
64.72
4,878
1
Friedrichshain-Kreuzberg
268,225
20.16
13,187
2
Lichtenberg
259,881
52.29
4,952
3
Marzahn-Hellersdorf
248,264
61.74
4,046
4
Mitte
332,919
39.47
8,272
5
Neukölln
310,283
44.93
6,804
6
Pankow
366,441
103.01
3,476
7
Reinickendorf
240,454
89.46
2,712
8
Spandau
223,962
91.91
2,441
9
Steglitz-Zehlendorf
293,989
102.50
2,818
10
Tempelhof-Schöneberg
335,060
53.09
6,256
11
Treptow-Köpenick
241,335
168.42
1,406
We need to change Lichtenberg’s Borough name beacause there is another Lichtenberg village in Germany and it can be confused to us:
3.3 – Using Foursquare API, I will explore the neighborhoods of Berlin
CLIENT_ID = '**************' # Here goes your Foursquare ID
CLIENT_SECRET = '***************'
ACCESS_TOKEN = '************' # Here goes your FourSquare Access Token
VERSION = '20210505'
LIMIT = 50
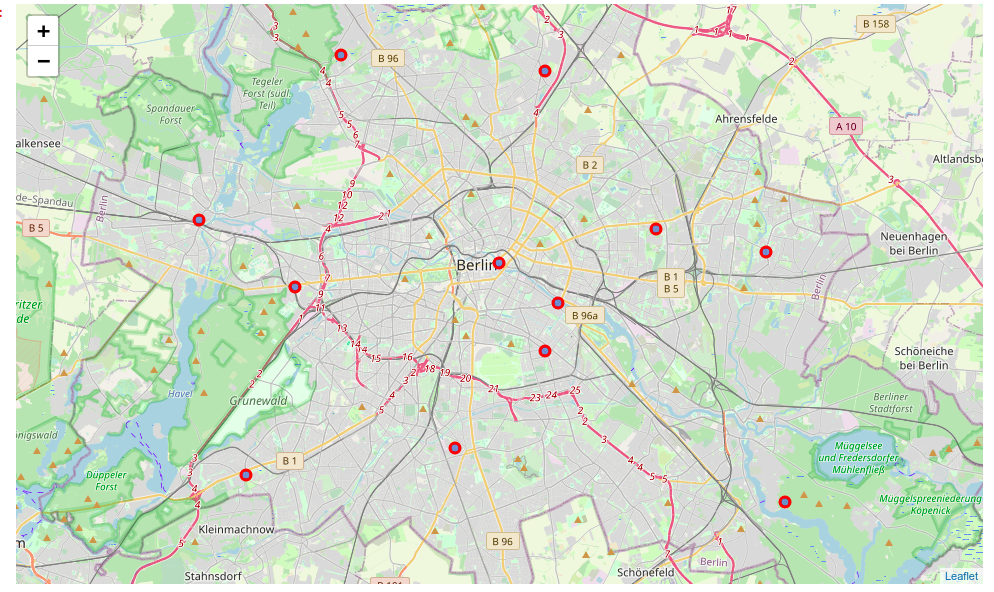
3.4 – Show venues in Mitte within a radius of 3500 meters.
neighborhood_latitude = df.loc[4, 'Latitude'] # neighborhood latitude value
neighborhood_longitude = df.loc[4, 'Longitude'] # neighborhood longitude value
neighborhood_name = df.loc[4, 'Borough'] # neighborhood name
print('Latitude and longitude values of {} are {}, {}.'.format(neighborhood_name,
neighborhood_latitude,
neighborhood_longitude))
Latitude and longitude values of Mitte are 52.5178855, 13.4040601.
# function that extracts the category of the venue
def get_category_type(row):
try:
categories_list = row['categories']
except:
categories_list = row['venue.categories']
if len(categories_list) == 0:
return None
else:
return categories_list[0]['name']
venues = results['response']['groups'][0]['items']
nearby_venues = json_normalize(venues) # flatten JSON
# filtering columns
filtered_columns = ['venue.name', 'venue.categories', 'venue.location.lat', 'venue.location.lng']
nearby_venues =nearby_venues.loc[:, filtered_columns]
# filtering the category for each row
nearby_venues['venue.categories'] = nearby_venues.apply(get_category_type, axis=1)
# cleaning columns
nearby_venues.columns = [col.split(".")[-1] for col in nearby_venues.columns]
nearby_venues
name
categories
lat
lng
0
Lustgarten
Garden
52.518469
13.399454
1
Kuppelumgang Berliner Dom
Scenic Lookout
52.518966
13.400981
2
Buchhandlung Walther König
Bookstore
52.521301
13.400758
3
Fat Tire Bike Tours
Bike Rental / Bike Share
52.521233
13.409110
4
LUSH
Cosmetics Shop
52.519844
13.410409
5
Ischtar-Tor
Exhibit
52.520742
13.397205
6
Pierre Boulez Saal
Concert Hall
52.515333
13.396218
7
James-Simon-Park
Park
52.521907
13.399361
8
Die Hackeschen Höfe
Monument / Landmark
52.524094
13.402157
9
Hotel de Rome
Hotel
52.516025
13.393938
10
Café 93
Café
52.522997
13.399752
11
BEN RAHIM
Coffee Shop
52.525168
13.401928
12
MA'LOA Poké Bowl
Poke Place
52.523653
13.400399
13
Monbijoupark
Park
52.523134
13.396894
14
Gendarmenmarkt
Plaza
52.513570
13.392720
15
Hackesche Höfe Kino
Indie Movie Theater
52.524148
13.402078
16
Kin-Za
Caucasian Restaurant
52.524928
13.395808
17
Konzerthaus Berlin
Concert Hall
52.513639
13.391795
18
Dussmann English Bookshop
Bookstore
52.518223
13.389239
19
Klub Kitchen
Bistro
52.524849
13.408988
20
Freundschaft
Wine Bar
52.518294
13.390344
21
Dussmann das KulturKaufhaus
Bookstore
52.518312
13.388708
22
Cuore di vetro
Ice Cream Shop
52.526577
13.408723
23
Luiban
Stationery Store
52.525728
13.410968
24
Deutscher Dom
History Museum
52.512747
13.392656
25
Banh Mi Stable
Sandwich Place
52.526965
13.408235
26
pro qm
Bookstore
52.527118
13.410147
27
Lafayette Gourmet
Gourmet Shop
52.514385
13.389569
28
Rausch Schokoladenhaus
Chocolate Shop
52.512289
13.391400
29
do you read me?!
Bookstore
52.527212
13.397701
print('{} venues were returned by Foursquare.'.format(nearby_venues.shape[0]))
30 venues were returned by Foursquare.
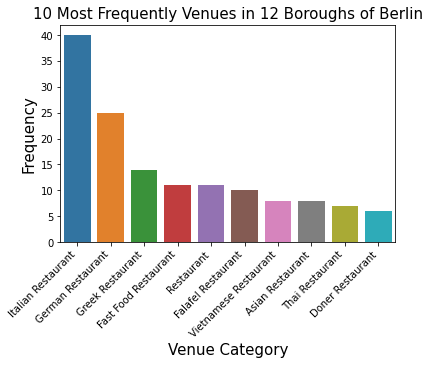
print ('{} unique categories in {}'.format(nearby_venues['categories'].value_counts().shape[0],neighborhood_name))
Bookstore 5
Concert Hall 2
Park 2
Monument / Landmark 1
Chocolate Shop 1
Hotel 1
Bistro 1
Café 1
Cosmetics Shop 1
Sandwich Place 1
Poke Place 1
Wine Bar 1
Ice Cream Shop 1
Bike Rental / Bike Share 1
Caucasian Restaurant 1
Coffee Shop 1
Garden 1
Exhibit 1
Gourmet Shop 1
Indie Movie Theater 1
Name: categories, dtype: int64
3.5 – Exploration of the neighbourhoods in Berlin
def getNearbyVenues(names, latitudes, longitudes, radius=3500, LIMIT=1000):
venues_list=[]
for name, lat, lng in zip(names, latitudes, longitudes):
print(name)
# create the API request URL
url = 'https://api.foursquare.com/v2/venues/explore?&client_id={}&client_secret={}&v={}&ll={},{}&radius={}&limit={}'.format(
CLIENT_ID,
CLIENT_SECRET,
VERSION,
lat,
lng,
radius,
LIMIT)
# make the GET request
results = requests.get(url).json()["response"]['groups'][0]['items']
# return only relevant information for each nearby venue
venues_list.append([(
name,
lat,
lng,
v['venue']['name'],
v['venue']['location']['lat'],
v['venue']['location']['lng'],
v['venue']['categories'][0]['name']) for v in results])
nearby_venues = pd.DataFrame([item for venue_list in venues_list for item in venue_list])
nearby_venues.columns = ['Neighborhood',
'Neighborhood Latitude',
'Neighborhood Longitude',
'Venue',
'Venue Latitude',
'Venue Longitude',
'Venue Category']
return(nearby_venues)
num_top_venues = 10
indicators = ['st', 'nd', 'rd']
# create columns according to number of top venues
columns = ['Neighborhood']
for ind in np.arange(num_top_venues):
try:
columns.append('{}{} Most Common Venue'.format(ind+1, indicators[ind]))
except:
columns.append('{}th Most Common Venue'.format(ind+1))
# create a new dataframe
neighborhoods_venues_sorted = pd.DataFrame(columns=columns)
neighborhoods_venues_sorted['Neighborhood'] = berlin_grouped['Neighborhood']
for ind in np.arange(berlin_grouped.shape[0]):
neighborhoods_venues_sorted.iloc[ind, 1:] = return_most_common_venues(berlin_grouped.iloc[ind, :], num_top_venues)
neighborhoods_venues_sorted.head(23)
Neighborhood
1st Most Common Venue
2nd Most Common Venue
3rd Most Common Venue
4th Most Common Venue
5th Most Common Venue
6th Most Common Venue
7th Most Common Venue
8th Most Common Venue
9th Most Common Venue
10th Most Common Venue
0
Charlottenburg-Wilmersdorf
Italian Restaurant
German Restaurant
Vietnamese Restaurant
Asian Restaurant
Greek Restaurant
Indian Restaurant
Mediterranean Restaurant
Falafel Restaurant
Argentinian Restaurant
French Restaurant
1
Friedrichshain-Kreuzberg
Falafel Restaurant
Middle Eastern Restaurant
Thai Restaurant
African Restaurant
Mediterranean Restaurant
Lebanese Restaurant
Italian Restaurant
Spanish Restaurant
German Restaurant
French Restaurant
2
Lichtenberg Berlin
Vietnamese Restaurant
Italian Restaurant
Greek Restaurant
German Restaurant
Syrian Restaurant
Indian Restaurant
Ramen Restaurant
Middle Eastern Restaurant
Moroccan Restaurant
New American Restaurant
3
Marzahn-Hellersdorf
Italian Restaurant
Fast Food Restaurant
Greek Restaurant
Restaurant
Mexican Restaurant
Asian Restaurant
Thai Restaurant
Syrian Restaurant
Sushi Restaurant
Spanish Restaurant
4
Mitte
Seafood Restaurant
Vegetarian / Vegan Restaurant
Caucasian Restaurant
Italian Restaurant
Middle Eastern Restaurant
Ramen Restaurant
Restaurant
Mexican Restaurant
Moroccan Restaurant
New American Restaurant
5
Neukölln
African Restaurant
Falafel Restaurant
Vegetarian / Vegan Restaurant
Turkish Restaurant
Spanish Restaurant
Restaurant
Korean Restaurant
Dumpling Restaurant
Vietnamese Restaurant
Sushi Restaurant
6
Pankow
Greek Restaurant
Italian Restaurant
Restaurant
Asian Restaurant
Chinese Restaurant
Doner Restaurant
Thai Restaurant
Mexican Restaurant
German Restaurant
African Restaurant
7
Reinickendorf
Italian Restaurant
German Restaurant
Restaurant
Indian Restaurant
Seafood Restaurant
Greek Restaurant
Eastern European Restaurant
Argentinian Restaurant
Sushi Restaurant
New American Restaurant
8
Spandau
Italian Restaurant
German Restaurant
Fast Food Restaurant
Argentinian Restaurant
Turkish Restaurant
Restaurant
Vietnamese Restaurant
Halal Restaurant
Greek Restaurant
Mexican Restaurant
9
Steglitz-Zehlendorf
Italian Restaurant
German Restaurant
Asian Restaurant
Doner Restaurant
French Restaurant
Fast Food Restaurant
Restaurant
Greek Restaurant
Mexican Restaurant
Sushi Restaurant
10
Tempelhof-Schöneberg
Italian Restaurant
Asian Restaurant
Thai Restaurant
Chinese Restaurant
Doner Restaurant
Fast Food Restaurant
Korean Restaurant
Greek Restaurant
Restaurant
Middle Eastern Restaurant
11
Treptow-Köpenick
German Restaurant
Fast Food Restaurant
Sushi Restaurant
Greek Restaurant
Seafood Restaurant
Restaurant
Middle Eastern Restaurant
Moroccan Restaurant
New American Restaurant
Ramen Restaurant
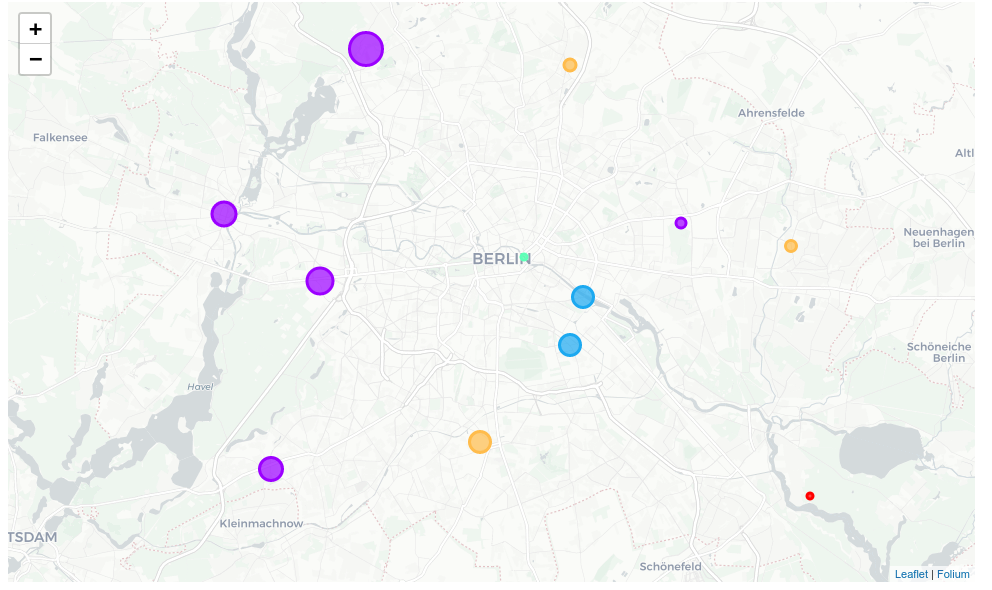
3.11 – Clustering the neighbourhoods with k-means.
# set number of clusters
kclusters = 5
berlin_grouped_clustering = berlin_grouped.drop('Neighborhood', 1)
# run k-means clustering
kmeans = KMeans(n_clusters=kclusters, random_state=0).fit(berlin_grouped_clustering)
# check cluster labels generated for each row in the dataframe
kmeans.labels_[0:10]
# create a map with folium
map_restaurants_10 = folium.Map(location=[latitude,longitude], tiles='cartodbpositron',
attr="<a href=https://github.com/python-visualization/folium/>Folium</a>")
# set color scheme for the five clusters
x = np.arange(kclusters)
ys = [i + x + (i*x)**2 for i in range(kclusters)]
colors_array = cm.rainbow(np.linspace(0, 1, len(ys)))
rainbow = [colors.rgb2hex(i) for i in colors_array]
# add markers to the map
for lat, lon, poi, cluster in zip(berlin_merged['Latitude'],
berlin_merged['Longitude'],
berlin_merged['Borough'],
berlin_merged['Nº Cluster']):
label = folium.Popup(str(poi) + ' Nº Cluster ' + str(cluster), parse_html=True)
folium.CircleMarker(
[lat, lon],
radius=list_rest_no[list_dist.index(poi)]*0.5,
popup=label,
color=rainbow[cluster-1],
fill=True,
fill_color=rainbow[cluster-1],
fill_opacity=0.7).add_to(map_restaurants_10)
map_restaurants_10
3.12 – Examination of the 5 clusters.
Now, we can examine each cluster and determine the discriminating venue categories that distinguish each cluster. Based on the defining categories, we can then assign a name to each cluster.